The 10 best coding LLMs in 2026: capability vs price — and the best combination for GeneXus with KBbridge
AI coding models change almost weekly: a new one ships, another drops its price, another opens its weights. So this post is a dated snapshot — June 2026 — built from public leaderboards, not an eternal truth. The goal is twofold: to see, without the hype, which models lead at coding and at what price; and, if you build on GeneXus, which combination is worth using with KBbridge — and why the answer isn't "just one."
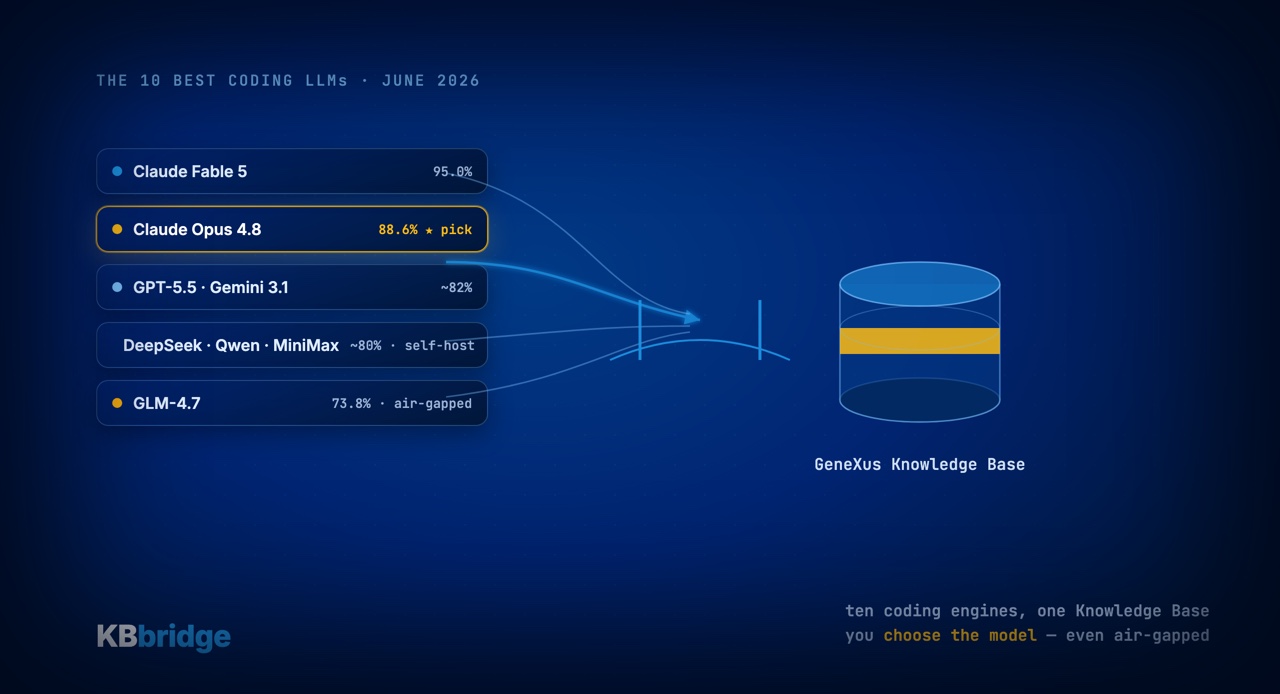
The top 10 for coding (June 2026)
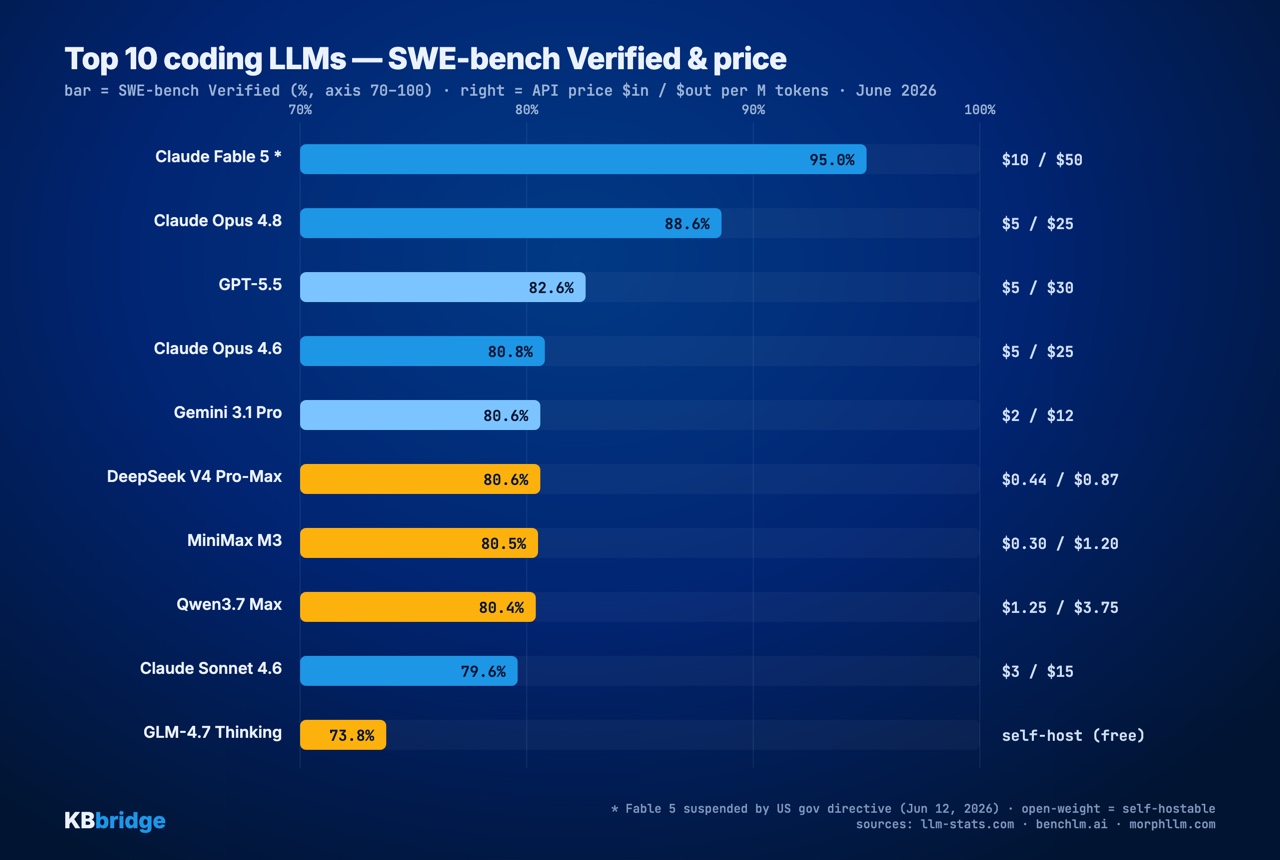
We use SWE-bench Verified as the capability axis: it measures whether a model resolves real software issues (with passing tests), a much better proxy for assisted coding than a loose code-generation benchmark. Price is USD per million tokens (input / output).
| # | Model | Provider | SWE-bench Verified | Price in / out | Open-weight |
|---|---|---|---|---|---|
| 1 | Claude Fable 5 * | Anthropic | 95.0% | $10 / $50 | No |
| 2 | Claude Opus 4.8 | Anthropic | 88.6% | $5 / $25 | No |
| 3 | GPT-5.5 | OpenAI | 82.6% | $5 / $30 | No |
| 4 | Claude Opus 4.6 | Anthropic | 80.8% | $5 / $25 | No |
| 5 | Gemini 3.1 Pro | 80.6% | $2 / $12 | No | |
| 6 | DeepSeek V4 Pro-Max | DeepSeek | 80.6% | $0.44 / $0.87 | Yes (MIT) |
| 7 | MiniMax M3 | MiniMax | 80.5% | $0.30 / $1.20 | Yes |
| 8 | Qwen3.7 Max | Alibaba | 80.4% | $1.25 / $3.75 | Yes |
| 9 | Claude Sonnet 4.6 | Anthropic | 79.6% | $3 / $15 | No |
| 10 | GLM-4.7 Thinking | Zhipu | 73.8% | self-host | Yes |
Update — June 14, 2026: three days after launch, a US government export-control directive forced Anthropic to suspend Claude Fable 5 (currently suspended — see the note above) (and Mythos 5): first for foreign nationals and, unable to filter them in real time, for everyone. That's why we flag it with
*: it is currently unavailable. We keep it in the table as a capability reference — and, fittingly, it's the best proof of this post's thesis: models appear and vanish overnight, so don't tie your KB to any single one. Source: Anthropic's statement.
Three things jump out. Anthropic sets the ceiling (Fable 5 and Opus 4.8 pull clearly ahead). Then there's a huge pack bunched around 80%: GPT-5.5, Gemini, the mid Claudes, and almost every open-weight model land within three points of each other. And the open-weight models — DeepSeek, MiniMax, Qwen, GLM — make the top 10 at a fraction of the price, and you can run them on your own infrastructure.
Capability vs price: the chart that matters
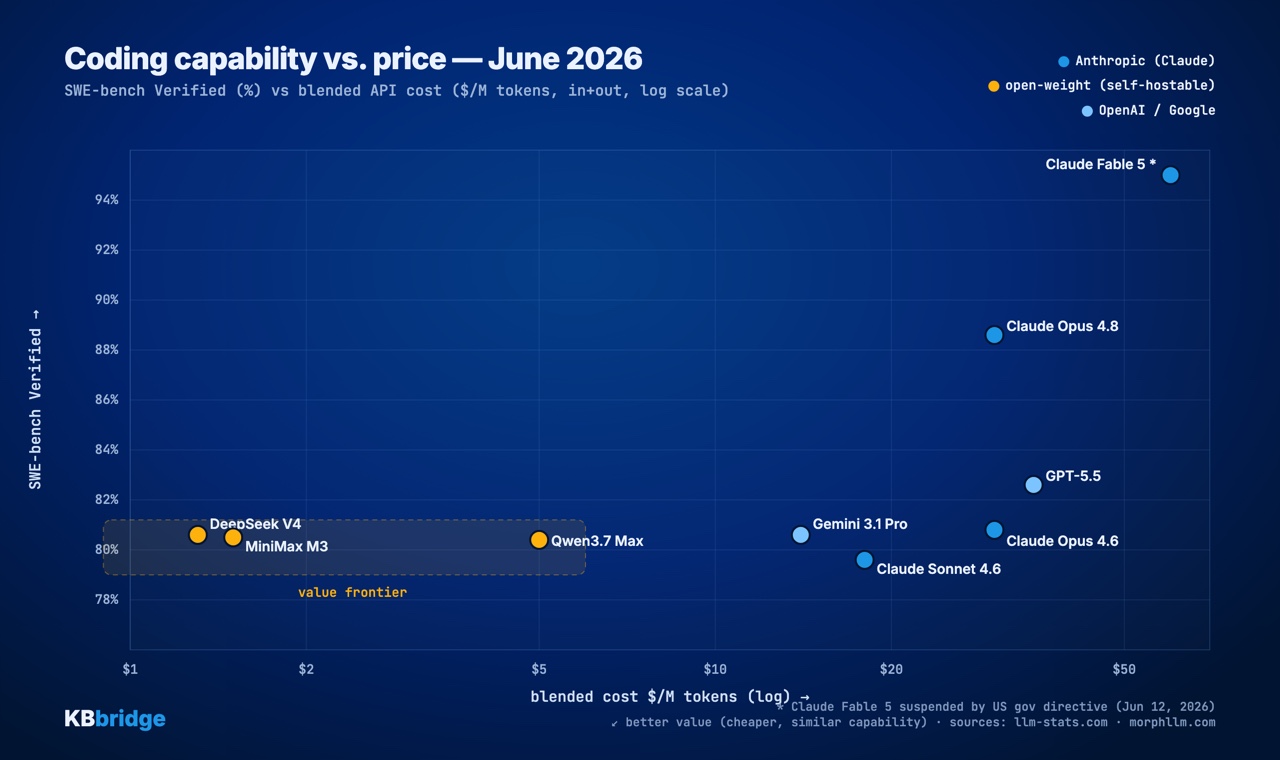
Here's the takeaway that earns the post. In the ~80% Verified band, prices range from $0.30/$1.20 (MiniMax) to $5/$25 (Opus 4.6) — up to 15x for near-identical capability. Only Fable 5 (95%) and Opus 4.8 (88.6%) truly break away, and you pay for it.
The practical lesson: for the bulk of coding work, a cheap model from the pack is more than enough. You reserve the premium for the hardest 5% — a big refactor, an elusive bug, a delicate migration. Paying frontier rates for everything is burning money.
What the benchmark doesn't tell you
- Context window: almost all of them sit near 1M tokens today, so it's no longer a differentiator.
- Agentic vs raw generation: SWE-bench Verified rewards completing whole tasks (read, edit, run tests), which is what you actually do with an in-editor assistant. A model that "writes pretty" but can't close the loop underperforms in practice.
- Open weights = data residency: if you can self-host, you decide where it runs and what leaves your network.
- The scaffold matters more than the model: the tooling around the model — what context it gets, what it can run, how it validates — moves the needle more than swapping one frontier model for another. That's why how you connect the model to your Knowledge Base matters.
The best combination for GeneXus + KBbridge
KBbridge is provider-agnostic: once your KB is externalized to text, any LLM that can read text can work on it. So the "best choice" isn't a model — it's a tiered strategy:
- Daily driver (agentic, inside KB Editor): Claude Opus 4.8, the best at agentic SWE-bench at a reasonable frontier price; and Claude Fable 5 for the hardest 5%. With a simple prompt, connecting Claude to KB Editor, I built an MCP server in about 6 hours, generated directly in GeneXus, with no need for Node.js or Python.
- High volume / cost-sensitive: DeepSeek V4 or MiniMax M3 — ~80% capability at a tenth of the price. Great for bulk generation, writing tests, documentation.
- Regulated / banking / government / Japan (air-gapped): self-host GLM-4.7, DeepSeek or Qwen on-prem against your KB. Nothing leaves your network. This is where KBbridge shines: local externalization, a 100% offline documentation engine, and you choose the model.
And the underlying point: since the models change every month — you just saw it in this very post — locking yourself to one is the mistake. KBbridge keeps your KB as plain text in your own Git: you switch models whenever a better or cheaper one appears, without touching your Knowledge Base. It's the same old GeneXus thesis — knowledge outlives technology — applied to the LLM era.
How you connect it, in one line
KBbridge externalizes your KB to text and auto-deploys the context files (CLAUDE.md, CODEX.md, .cursorrules, and the rest), so any of these models — via Claude Code, Copilot, Cursor, or your self-hosted model — opens your project already knowing it's GeneXus. The documentation engine (46,750 doc chunks) runs offline, with no API keys and no outbound traffic.
Sources and fine print
Data as of June 2026; it changes fast, so treat it as a snapshot, not a constant. Benchmarks and pricing from:
- llm-stats.com — SWE-bench Verified leaderboard and best AI for coding
- Morph — Best AI Model for Coding (June 2026) and SWE-bench Pro Leaderboard
- BenchLM — LLM API Pricing 2026
- CodeAnt — SWE-bench Leaderboard 2026
Want to try any of these models on your own GeneXus KB? Watch the short videos on Getting Started, or try it free for 15 days, no card required, at kbbridge.com.